
Virksomheder indsamler ikke længere clickstream-data med Google Analytics 4 (GA4) udelukkende for at muliggøre datainformeret beslutningstagning ved at inspicere og analysere de indsamlede brugerdata, vurdere marketingkampagnens resultater eller rapportere om de mest værdifulde landingssider. Virksomheder, der ønsker at skabe konkret forretningsværdi, bruger det som et dataindsamlingsværktøj, der fodrer deres marketingplatforme med konverteringer og værdifulde målgrupper.
Sådan har det altid været, men med fremkomsten af GTM Server-Side (sGTM) og dets voksende muligheder bliver denne integration mere dybtgående.
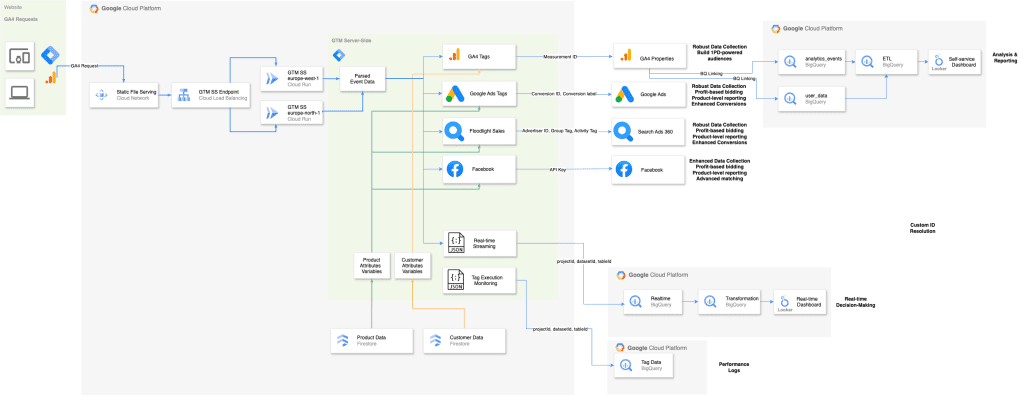
Som illustreret i ovenstående visualisering migrerer virksomheder deres dataindsamling til tjenester som Google Ads, Meta, Floodlight og andre fra deres klient-side til server-side containere. Dette skift giver betydelige fordele, herunder yderligere datakontrol, optimeret sideindlæsningshastighed og mulighed for at berige datastrømme med førstepartsdata i realtid. Denne forbedrede dataindsamlingsstrategi åbner op for muligheder for tilpassede løsninger som dashboards i realtid og personlig kommunikation.
Mens skiftet til GA4 og sGTM er et positivt skridt, der potentielt kan forbedre den digitale markedsføringsydelse (læs en af vores cases om, hvordan man udnytter sGTM til at forbedre markedsføringsydelsen her), medfører det også en ny udfordring, som indtil videre er gået hen over hovedet på dem, der har travlt med at indføre denne tilgang. Det stigende antal leverandører og værktøjer, der er afhængige af en enkelt GA4-datastrøm, fremhæver den kritiske betydning af nøjagtig dataindsamling. Virksomheder skal prioritere datakvalitet for at sikre effektiviteten af deres digitale marketingstrategier.
Det traditionelle QA-flow: En opskrift på at miste tillid
Den kompleksitet og de risici, der er forbundet med den dominerende tilgang, bliver tydelige, når vi undersøger den nuværende tilstand af datakvalitetssikring (QA) i organisationer.
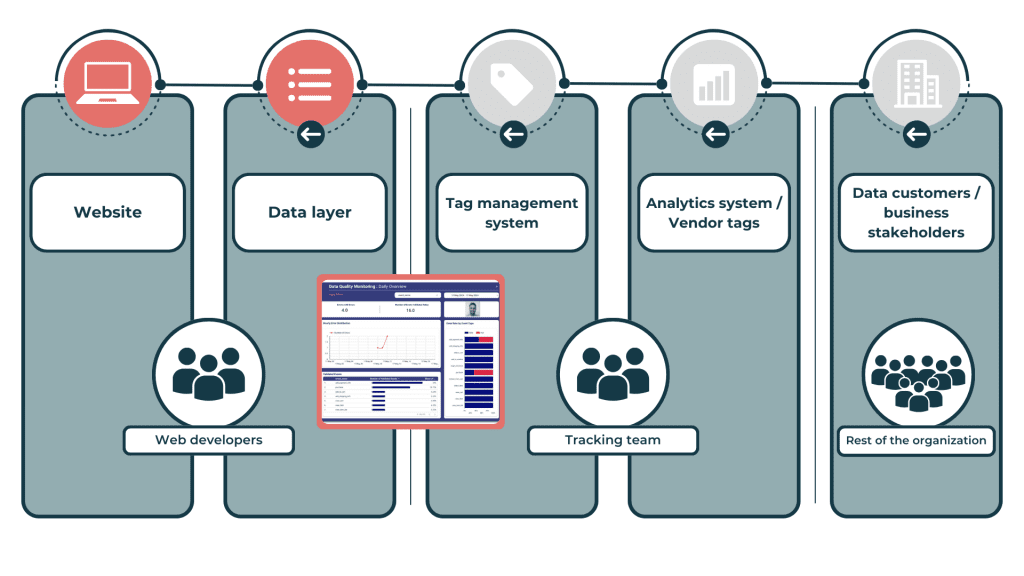
Den traditionelle QA-proces for GA4-dataindsamling samt måleimplementeringer for andre marketingleverandører involverer flere afdelinger og forskellige lag – som du kan se i figuren nedenfor. Normalt samarbejder webstedsudviklere og måleteamet om dataLayer-specifikationerne og deres implementering. De eksponerede hændelser og tilknyttede værdier driver tag management-systemet (f.eks. Google Tag Manager), hvor GA4-tags er konfigureret til at udløses, læse de ønskede værdier og sende dem til GA4-serverne. Til sidst gøres de behandlede data tilgængelige for en bred vifte af dataforbrugere og beslutningstagere i organisationen via GA4 UI eller dedikerede dashboards.
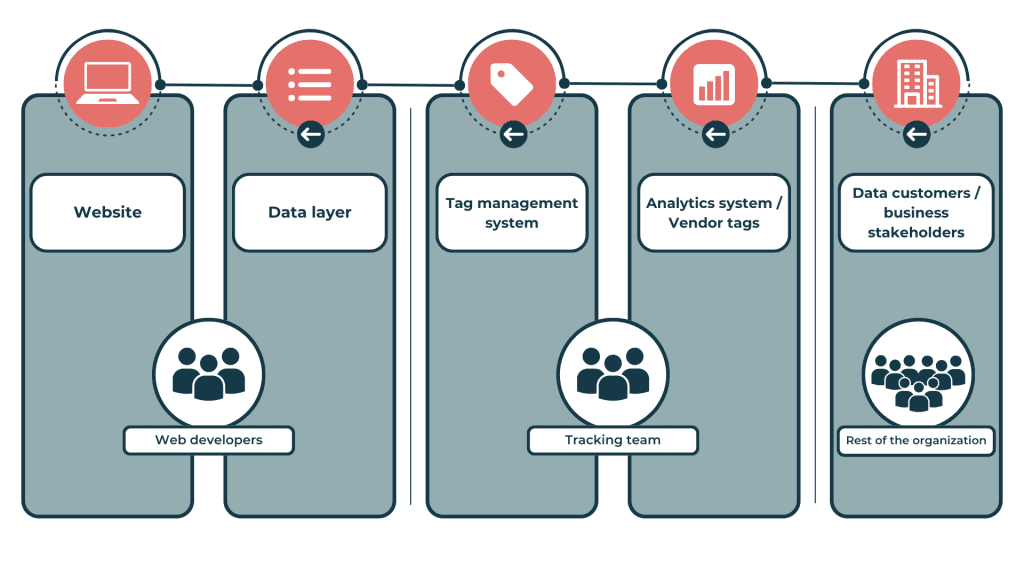
Når der ikke er indført GA4-datakvalitetsforanstaltninger, identificerer datamodtagerne normalt uoverensstemmelser i data og rapporterer deres resultater videre til dig og dine kolleger i måleteamet. Hvis du nogensinde har fået et opkald eller en e-mail, der påpeger uoverensstemmelser i din dataindsamling, mens du var ved at gøre dig klar til weekenden, kan du forstå, hvordan det kan ødelægge dine weekendplaner (det kan jeg i hvert fald). Når du modtager denne besked, begynder arbejdet: Dit team undersøger, om de kan bekræfte problemet, eller om modtagerne mangler kontekst eller træning. Hvis de kan bekræfte problemet, skal de identificere kilden – sandsynligvis ved at forsøge at replikere det. I den proces skal de kommunikere med dataforbrugerne og webudviklerne, før synderen er identificeret og til sidst løst.
Du kan se, hvor frustrerende besværlig denne proces er. Men det er stadig sådan, de fleste virksomheder arbejder derude. Med et så langt QA-flow kan fejl sprede sig hurtigt og påvirke flere områder, før de opdages. Desuden øger inddragelsen af forskellige afdelinger svartiderne og forsinker løsningen af fejl. Utilstrækkelige værktøjer forhindrer ofte effektiv fejlfinding i stor skala.
Konsekvenserne af disse mangler er alvorlige:
- Forsinket indsigt: Fejl fundet af dataforbrugere betyder ofte, at dataene har været forkerte i en periode, hvilket fører til forsinket eller misforstået indsigt.
- Reduceret tillid: Gentagne fejl opdaget af slutbrugere kan underminere tilliden til analyseplatformen og gøre interessenter mindre trygge ved dataene.
- Øget arbejdsbyrde: Dataforbrugere, sporingsteams og udviklingsteams står alle over for en øget arbejdsbyrde med at identificere, rapportere og løse problemer, hvilket kan aflede ressourcer fra mere strategiske initiativer.
- Ineffektivitet i driften: At finde og rette fejl efter indsamlingen fører til ineffektivitet i driften.
Fra reaktiv til proaktiv overvågning af datakvalitet
For at overvinde problemerne med denne reaktive tilgang bør du som ansvarligt medlem af dit sporingsteam udvikle proaktive foranstaltninger, der fanger fejl så tidligt som muligt, før de manifesterer sig og bliver eksponeret som fakta for dine dataforbrugere. Lad os derfor udforske nogle af de muligheder, vi har til rådighed, lige fra indbyggede GA4-funktioner til udnyttelse af BQ-rådataeksporten og implementering af et brugerdefineret valideringsendpunkt i det følgende afsnit.
Udnyttelse af GA4 Insights
GA4 har en indbygget indsigtsfunktion, der automatisk kan registrere ændringer i dine data. Ved at oprette brugerdefinerede alarmer (ja, det er svært at give slip på de gode gamle UA-terminologier) kan du overvåge vigtige dataændringer og modtage e-mailnotifikationer, når visse definerede betingelser er opfyldt. Du kan f.eks. oprette alarmer for betydelige fald i aktive brugere eller købshændelser, hvilket sikrer rettidig indgriben.
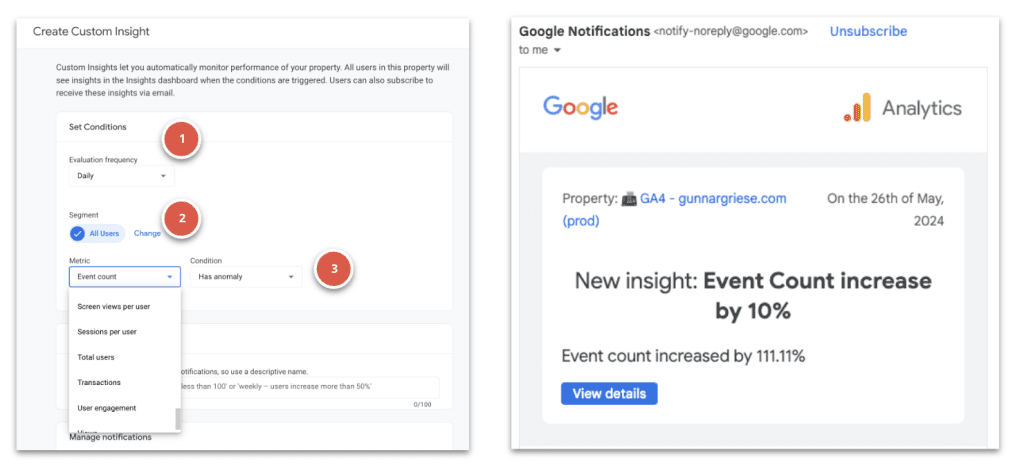
Konfigurationen er enkel og giver mulighed for en hel del fleksibilitet:
- Evalueringsfrekvens: Hver time (kun web), dagligt, ugentligt, månedligt
- Segment: Alle brugere er standardsegmentet. Skift for at vælge andre dimensioner og dimensionsværdier. Angiv, om segmentet skal inkluderes eller ekskluderes
- Metric: Vælg metric, betingelse og værdi for at indstille den tærskel, der udløser indsigten. For eksempel: 30-dages aktive brugere – % fald med mere end – 20. Hvis du vælger Har anomali som betingelse, bestemmer GA4, hvornår ændringen i metrikken er anomal, og du behøver ikke at indtaste en værdi.
Muligheden for at opsætte disse notifikationer er et godt skridt i den rigtige retning, da det øger chancerne for, at måleteamet opdager fejl i dataindsamlingsmekanismen i stedet for at lægge denne opgave over på dataforbrugerne. Ved at flytte kvalitetssikringen tættere på kilden får vi værdifuld tid og kontrol over håndteringen af disse problemer (især fra et kommunikationsperspektiv til vores slutbrugere).
Den brugerdefinerede indsigtsfunktion er fremragende til at opdage uventede udsving (=datavolumen) i relevante målinger, og vigtigst af alt er den gratis. Alligevel er den ikke i stand til at løse potentielle problemer med datakvaliteten. For at gøre det har vi brug for meget mere detaljerede konfigurationsmuligheder, så vi kan udføre kontroller på hændelsesniveau.
Vi forbedrer vores spil med BigQuery og Dataform
Jeg er ikke den første, der fortæller dig det, men her kommer det: Eksport af dine GA4-rådata til BQ vil hjælpe dig med at få mest muligt ud af dine GA4-data. I dette tilfælde er det vores gateway til at implementere effektive datakvalitetskontroller for vores data.
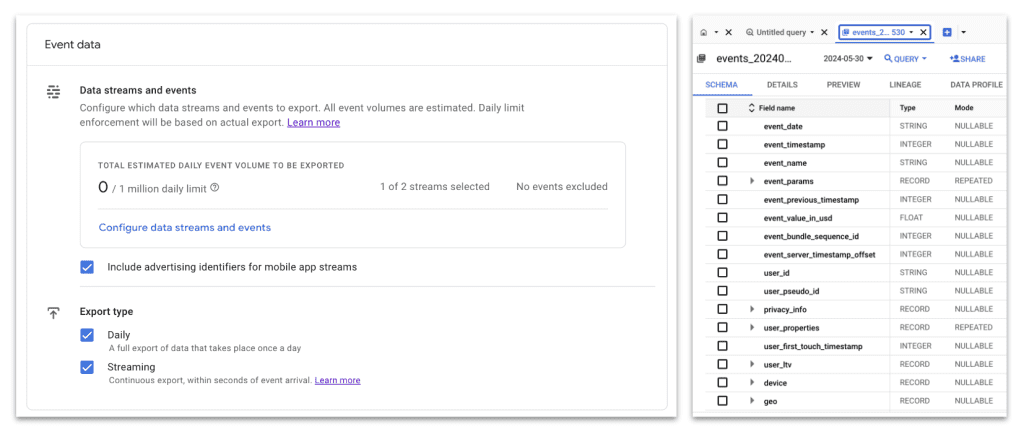
Ved at integrere BigQuery med din GA4-opsætning kan du implementere brugerdefinerede evalueringsregler ved hjælp af SQL – kun begrænset af din fantasi. Denne integration gør BigQuery til et kraftfuldt værktøj til overvågning af datakvalitet.
Ved hjælp af SQL i BigQuery er det muligt at udvikle tilpassede regler til at evaluere dine data. Du kan f.eks. opsætte regler til at validere event-datastrukturer og sikre, at de lever op til dine foruddefinerede standarder. For at give dig lidt inspiration:
- Spores alle de forventede e-handelsbegivenheder?
- Har alle disse begivenheder et element-array, der er knyttet til mindst ét element?
- Har alle varer et vare-id, en mængde og en værdi?
- Har alle købshændelser et transaktions-ID (i det forventede format), og er købsindtægten større end 0?
- Og så videre.
Det er op til dig at pakke din forretningslogik ind i en SQL-forespørgsel, der beregner andelen af “falsy”-hændelser og identificerer mønstre for, hvorfor det sker (f.eks. specifikke sidestier eller browsere). Nu spørger du måske dig selv: Forventer du virkelig, at jeg skal køre sådan en forespørgsel ved slutningen af hver dag, før jeg går hjem?
Nej, ikke nødvendigvis. Du kan bruge Dataform til at forbedre dette yderligere ved at give dig mulighed for at opbygge og operationalisere skalerbare datatransformationspipelines. Dataform vil især gøre det muligt for dig at lette arbejdet med at planlægge og evaluere resultaterne af datakvalitetsforespørgsler. Dataform giver dig mulighed for nemt at planlægge forespørgsler og implementere valideringer oven på forespørgselsresultater ved hjælp af assertions.
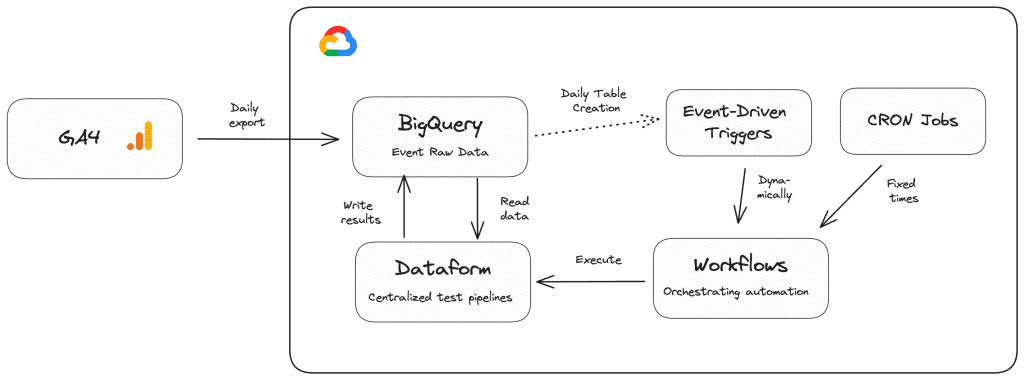
I nedenstående Dataform-konfiguration spørger jeg f.eks. efter sidevisninger fra min blog, hvor den brugerdefinerede dimension forfatter ikke er udfyldt. Desuden specificerer jeg en regel om, at andelen af disse “dårlige” sidevisninger ikke må være mere end 10 % af alle målte sidevisninger ved hjælp af Dataforms assert-funktion .

Mange af jer bruger måske allerede Dataform i deres arbejdsgange til at automatisere oprettelsen af aggregerede datasæt til rapportering, og det kræver kun minimalt ekstra arbejde at tilføje datakvalitetserklæringer til blandingen, men det sikrer, at du og dit team leverer data af høj kvalitet til jeres slutbrugere. Hvis du ikke har kigget på Dataform endnu, kan jeg varmt anbefale at tjekke det ud – gå ikke glip af en enorm tidsbesparelse.
Datavalidering i realtid
Men ville det ikke være endnu bedre, hvis vi på en eller anden måde kunne flytte evalueringen af datakvaliteten op til det punkt, hvor dataene faktisk stammer fra, og dermed muliggøre realtidsovervågning af alle de begivenheder, vi indsamler? Hvis det var tilfældet, kunne vi reagere endnu hurtigere på fejl og rette fejl, før flere dages data bliver kompromitteret. Vi kunne styre kommunikationen omkring, hvordan vi skal håndtere disse fejl. Vi kunne endda beslutte, hvad vi skulle gøre med disse fejlagtige data, før de kom ind i nogen downstream-systemer (- kan du huske det første billede i denne artikel?).
Fordelene ved en sådan realtidsvalidering er enorme, og den kan muliggøre en meget mere strømlinet QA-proces for vores GA4-data.
Begreberne skemaer og datakontrakter
GA4-dataindsamlingen for hjemmesider stammer naturligvis fra vores brugeres browsere, når de besøger vores hjemmeside. Vi aktiverer derefter sporing af relevante brugerinteraktioner via webstedets dataLayer (især til sporing af e-handel) og bruger dataLayer-hændelserne til at udløse vores GA4-hændelsestags, som også opsamler metadata i henhold til tags’ konfigurationer. Til sidst sendes hændelserne og de tilknyttede data via anmodninger direkte til GA4-servere eller vores egen sGTM-container til videre behandling.

Som oversigten ovenfor illustrerer, består alle tre GA4-datakilder af objekter og nøgleværdipar, der beskriver en given købshændelse og dens egenskaber. Derfor kan vi tænke på hver GA4-begivenhed som et JSON-objekt, der indeholder alle de nødvendige oplysninger om den, så den kan behandles i GA4.
Ovenstående JSON indeholder oplysninger om en bestemt begivenhed, men udelader detaljer, der kan føre til visse begrænsninger, når den sendes til GA4. For eksempel kan ovenstående JSON-objekter være:
- Uklart: Eksemplerne fortæller os ikke, hvilke felter der er obligatoriske eller valgfrie, eller hvad deres respektive typer er. F.eks. ved vi ikke, om transaktions-ID-feltet altid skal være en streng eller et tal. Hvis det skal være en streng, kender vi heller ikke dens format. Skal transaction_id altid starte med et “T-” som i eksemplet?
- Ufuldstændig: JSON-objekter mangler komplet datakontekst, f.eks. om et item-objekt skal indeholde et item_id- eller item_name-felt, og det angiver ikke, hvilke felter der kan udelades.
- Ingen håndhævelse: JSON-objekter mangler standardiseret validering og begrænsninger, så de kan ikke håndhæve regler som, at en begivenhed kræver et user_id, hvis login_status er lig med “loggedIn”, eller at item_category-værdien er fra en foruddefineret liste.
For standard GA4-begivenhederne giver Google os omfattende dokumentation for de nødvendige nøgleværdipar og værdiernes typer. Hvis du tidligere har været seriøs med din dataindsamling, kan du desuden være sikker på, at du også har dokumentation om brugerdefinerede hændelser og tilhørende parametre.
Behovet for at validere en forekomst af et JSON-objekt i forhold til et foruddefineret sæt regler, som dette objekt skal overholde, er heldigvis ikke noget nyt inden for programmering og er allerede blevet løst. En af de mest effektive måder at sikre datakonsistens og -validitet på er gennem JSON Schemas. JSON Schema er en plan for JSON-data, der løser alle de nævnte problemer. Det definerer de regler, den struktur og de begrænsninger, som dataene skal følge.
JSON Schema bruger et separat JSON-dokument til at levere JSON-datas plan, hvilket betyder, at selve skemaet også er maskin- og menneskelæsbart. Eller for at omformulere det: Vi bruger JSON til at beskrive JSON.
Lad os se på, hvordan skemaet for vores eksempel på en dataLayer-købshændelse ovenfor kunne se ud:
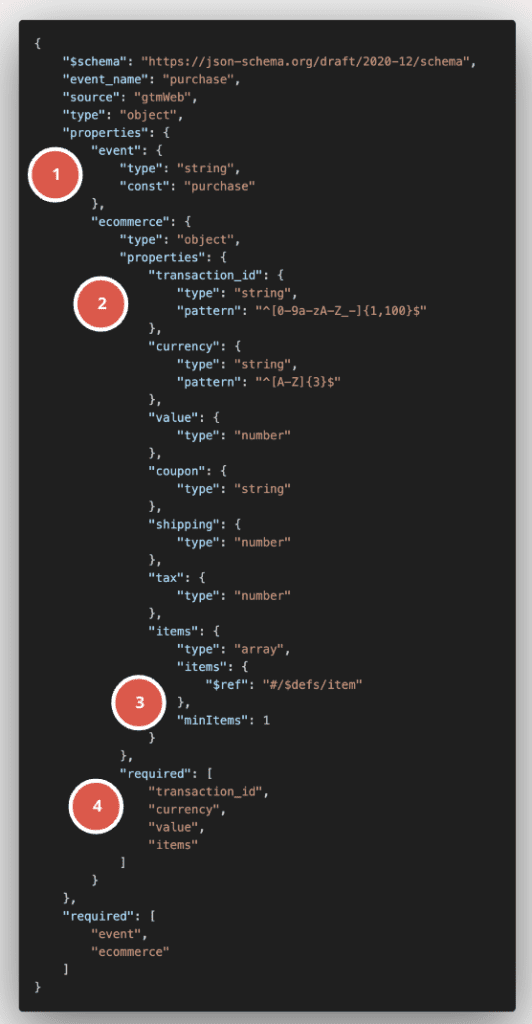
Som du kan se, giver skemaet ovenfor blandt andet meget mere kontekst til vores oprindelige purchase dataLayer-objekt:
- Tilladte værdier
- Mønsterbegrænsninger (RegEx-validering)
- Listevalidering (f.eks. minimum antal objekter i en liste)
- Nøglevalidering (f.eks. skal der være nøgleværdipar i et objekt)
Dette skema fungerer derefter som en slags datakontrakt, som alle GA4-begivenheder eller dataLayer-objekter skal overholde for at blive betragtet som gyldige.
Overvågning af et websites dataLayer
Med JSON-skemaet i vores værktøjskasse og GCP’s fulde kraft til rådighed kan vi nu sætte alle brikkerne sammen ved at bygge et letvægtsvalideringsendpunkt, der er i stand til at modtage dataLayer-hændelsesobjekter fra webstedet og validere dem i forhold til de skemaer, du har defineret.
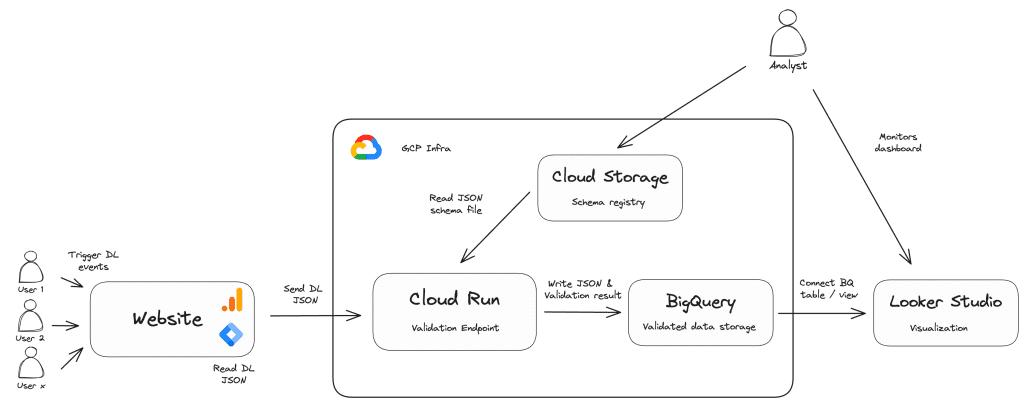
Det kræver et brugerdefineret HTML-tag i hjemmesidens container, som læser det ønskede dataLayer-objekt og sender det som payload til vores valideringsapplikation, der kan være hostet på Cloud Run, App Engine eller Cloud Functions. Applikationen vil læse skemadefinitionerne og sammenligne dem med de modtagne dataLayer-hændelser. Resultaterne af denne validering (f.eks. gyldig eller ej, potentielle fejlmeddelelser osv.) vil blive skrevet til BigQuery eller applikationens logfiler.
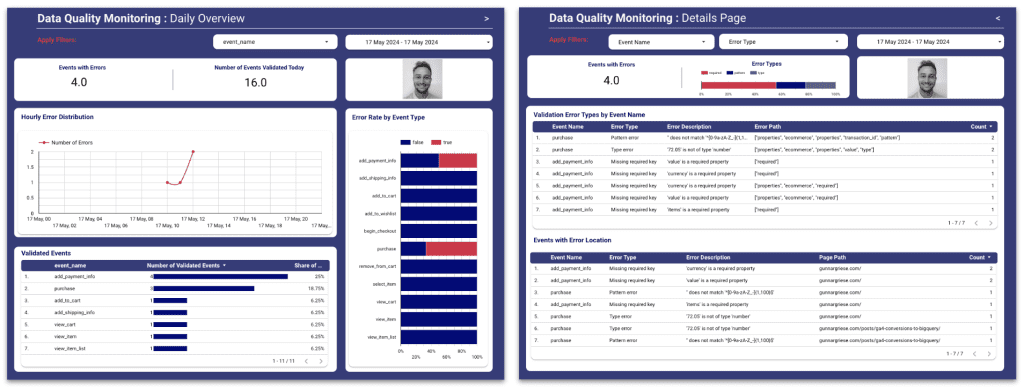
De resulterende BigQuery-tabeller giver mulighed for et datakvalitetscockpit, der kan deles med alle interessenter – især måleholdet og webudviklerne, der er ansvarlige for dataLayer-implementeringen. Det centraliserede dashboard kan give et overblik over din datakvalitetsstatus, advare dig om potentielle problemer og give dig mulighed for at træffe proaktive foranstaltninger.
Overvågning af GA4-begivenhedsstrømmen
Hvis vi bruger sGTM til vores GA4-dataindsamling, kan vi integrere vores brugerdefinerede valideringsslutpunkt med containeren ved at bruge en asynkron brugerdefineret variabel, der videresender hændelsesdataobjektet, der er analyseret af GA4-klienten, til validatorens slutpunkt. Tjenesten vil derefter svare med valideringsresultatet som nedenfor:

Når disse oplysninger er tilgængelige, før data stilles til rådighed for GA4 eller andre downstream-leverandører som G Ads, Meta eller andre, giver det fuld kontrol over, hvordan man behandler begivenheder, der er kompromitteret:
- Bør disse arrangementer helt droppes?
- Skal de dirigeres til en separat GA4-egenskab for yderligere undersøgelse?
- Skal kompromitterede begivenheder bruges til at udløse marketingtags?
- Skal GA4-begivenhederne blot beriges med en datakvalitetsparameter?
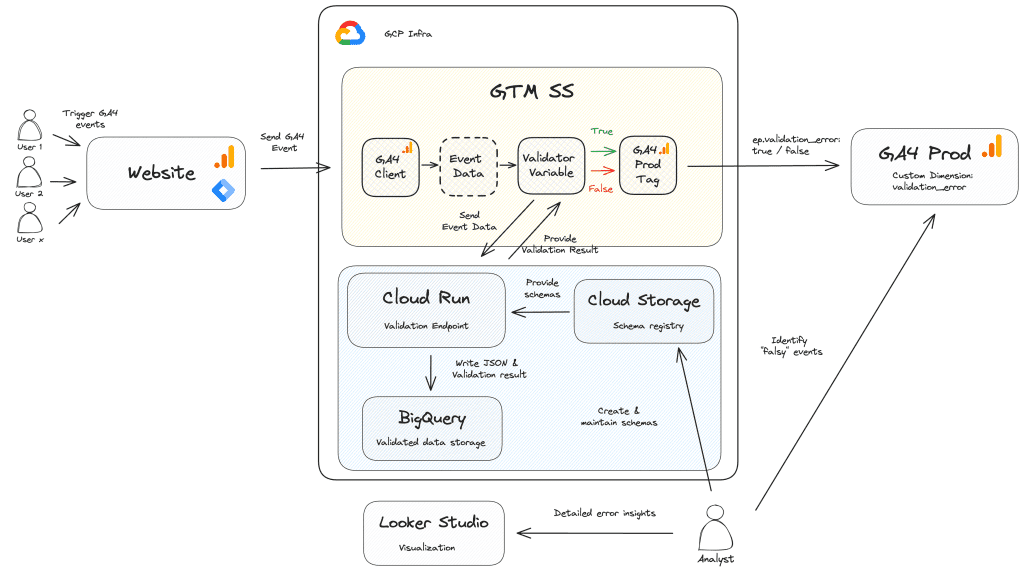
Mens den tidligere løsning er god til at overvåge din datakilde og få besked, når noget går i stykker, giver en direkte integration med sGTM og berigelse af GA4-datastrømmen i realtid faktisk mulighed for at håndhæve datakontrakten.
Fordele ved proaktiv overvågning af datakvalitet
Uanset hvilken løsning du vælger, giver proaktiv datakvalitet lige ved kilden til dataovervågning flere betydelige fordele, der sikrer, at dine analysedata forbliver nøjagtige, pålidelige og brugbare.
1. Øget tillid til data
Når data konsekvent er nøjagtige og pålidelige, udvikler interessenter større tillid til analyseplatformen. Denne tillid er afgørende for at kunne træffe informerede forretningsbeslutninger og lægge en effektiv strategi.
2. Operationel effektivitet
Ved at fange fejl tidligt i datapipelinen reducerer proaktiv overvågning behovet for omfattende rensning og korrektion af data efter indsamlingen. Denne effektivitet sparer tid og ressourcer, så teams kan fokusere på mere strategiske initiativer i stedet for brandslukning af dataproblemer.
3. Besparelser på omkostninger
Det er generelt billigere at identificere og løse problemer med datakvaliteten tidligt i processen end at løse dem, når de har påvirket downstream-systemer og -rapporter. Proaktiv overvågning hjælper med at undgå de økonomiske konsekvenser af dårlig datakvalitet for forretningsdriften.
4. Forbedret beslutningstagning
Data af høj kvalitet fører til bedre analyser og indsigt, som er afgørende for at træffe fornuftige forretningsbeslutninger. Proaktiv overvågning sikrer, at beslutningstagere har adgang til nøjagtige og rettidige oplysninger, hvilket reducerer risikoen for at træffe valg baseret på forkerte data.
Konklusion
Proaktiv overvågning af datakvalitet er ikke bare en bedste praksis; det er en nødvendighed i det moderne datalandskab. Ved at implementere robuste overvågnings- og valideringssystemer til deres adfærdsdataindsamling i GA4 kan organisationer sikre integriteten af deres data, opbygge interessenternes tillid og opretholde driftseffektiviteten. Overgangen fra reaktiv til proaktiv overvågning giver en strategisk fordel, der gør datakvalitetsstyring til en konkurrencemæssig differentiator.
Investering i proaktiv overvågning beskytter ikke kun dine data, men forbedrer også din organisations evne til at træffe rettidige, informerede og virkningsfulde beslutninger.
Hvis du har brug for yderligere hjælp eller vil diskutere, hvordan vi kan hjælpe dig med at sikre datakvalitet i stor skala, er du velkommen til at kontakte os hos IIH Nordic.
")




